
La première étape d'un moteur de recherche, c'est la récupération des données. Elle peut provenir de différentes sources, et se présenter sous plusieurs formats.
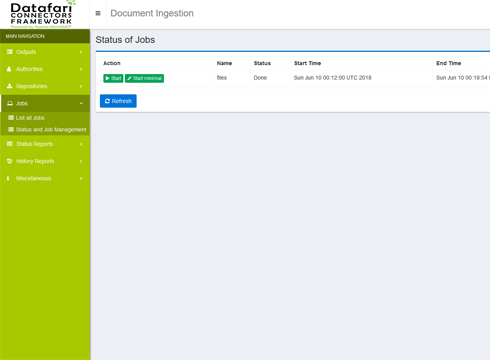
Administration
Une interface permet d'administrer les connecteurs, et la connexion au LDAP/AD si nécessaire. Elle permet de surveiller l'état du système et la récupération des documents.
Gestion de la charge
Gestion de la charge sur les sources de données, en nombre de threads, de documents récuperés, de taille des documents. Gestion de fenêtres temporelles de crawl.
Filtres de traitements
Possibilité de créer des filtres de traitements des données, avec notamment l'utilisation d'expression régulières pour inclure ou exclure des documents ou des repertoires.
Partages de fichiers
Indexation de vos partages de fichiers (Netapp, windows, samba, Dropbox...), de façon sécurisée. Gestion de l'OCR. Gère de nombreux formats comme ppt, xls, html, jpeg, MS office, open office...
GED et portails
Indexation de vos GED (Gestion Electronique de Documents), CMS ou portails (Liferay, Alfresco, Sharepoint, Documentum, Filenet, CMIS...), là encore de façon sécurisée.
Tout le reste
BDD, réseaux sociaux... Système de plugin pour développer des connecteurs supplémentaires. Vous pouvez les créer vous-même, ou vous appuyer sur nos compétences.

Après le crawling, c'est la seconde étape d'un moteur de recherche. Les données une fois récuperées des sources externes, doivent être ingérées par le moteur de recherche, et mises à disposition dans un index de recherche.
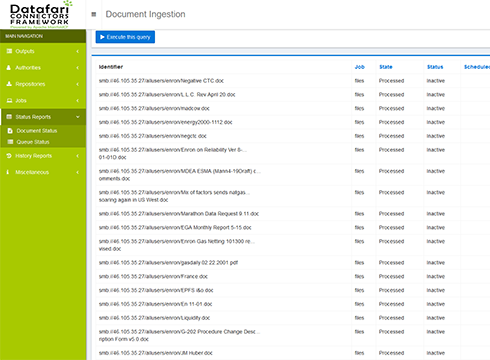
Scalabilité
Datafari est capable d'indexer plusieurs centaines de millions de documents, en se basant sur une architecture big data de style hadoop, sur plusieurs machines.
Fiabilité
En mode distribué, la technologie distribuée avec Zookeeper et SolrCloud permet la gestion automatique de la défaillance des systèmes.
Flexibilité
Gestion du quasi temps réel, de multiple types de données (int, string, date...), mode schema-less, possibilité d'ajout dynamique de champs.
Une fois le crawling et l'indexation terminés, c'est le moteur de recherche qui s'occupe d'interpréter les requêtes utilisateurs, et de trouver les données les plus pertinentes
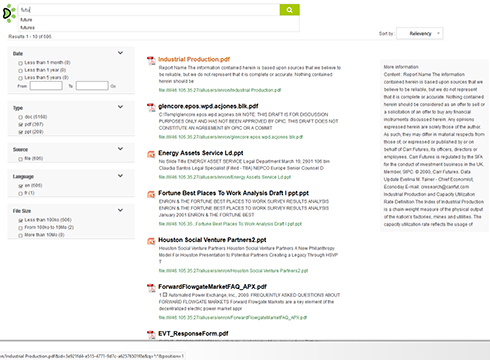
Big Data
Le moteur de recherche peut gérer plusieurs milliers de requêtes par seconde, en se basant sur une architecture big data de style hadoop, sur plusieurs machines.
Sémantique
Gestion multilingues, correction orthographique, suggestion de contenu, extraction d'entités (dates, lieux...), clusterisation des résultats, ...
Flexible
Son algorithme est entièrement customisable, pour l'algorithme comme pour les paramètres utilisés (pondération en temps réelle, choix des champs, recherche floue...).
Responsive Design
Ajaxfrancelabs est en Responsive Design, il s'affiche donc de façon ergonomique aussi bien sur grand écran que sur smartphone et tablette.
Alertes
Les utilisateurs peuvent enregistrer des requêtes, et être informés par email de documents (nouveaux ou modifiés) correspondant à ces requêtes.
Autocompletion Intelligente
L'autocompletion suggère des requêtes pour accélerer et améliorer le processus de recherche pour les utilisateurs.

En entreprise, la sécurité est un élément clé des applications. A toutes les phases de notre solution de recherche Datafari, la sécurité est là pour assurer la confidentialié des échanges ainsi que le respect des droits.
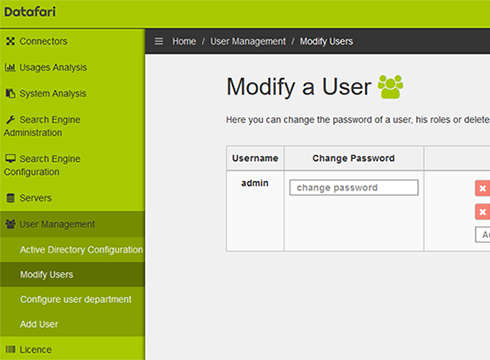
Authentification
Datafari peut se connecter à l'AD ou au LDAP en place pour authentifier l'utilisateur, mais permet aussi de gérer les utilisateurs de façon autonome.
Autorisation
Datafari se connecte à vos systèmes gérants les autorisations et les ACLs, afin de garantir qu'un utilisateur ne voit que ce qu'il est autorisé à voir.
Confidentialité
Activation de https pour les échanges entre les différents composants du système et les utilisateurs, ce qui permet un fort chiffrage des données.
Une solution d'entreprise doit proposer un outil d'administration permettant une prise en main rapide. C'est le cas avec Datafari.
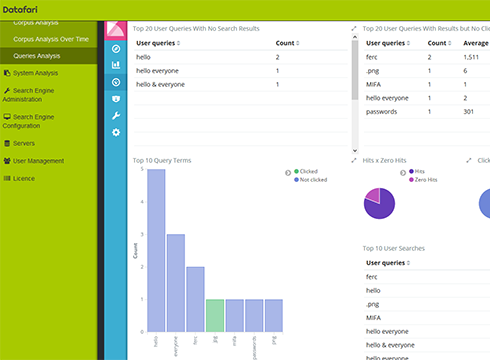
Pour l'administrateur
Administration des alertes, des serveurs, du cluster de machines, des utilisateurs, de la connexion à l'AD/LDAP...
Pour l'expert recherche
Administration des poids, des promoliens, des statistiques, des synonymes et des stopwords, déduplication...
Pour l'utilisateur
Administration des alertes, des likes (quand un résultat est apprécié), des favoris (mise en panier d'un résultat)

La Pertinence est un élément clé d'une moteur de recherche pour entreprise, notamment parce qu'un utilisateur ne revient pas deux fois s'il est déçu par les résultats de recherche.
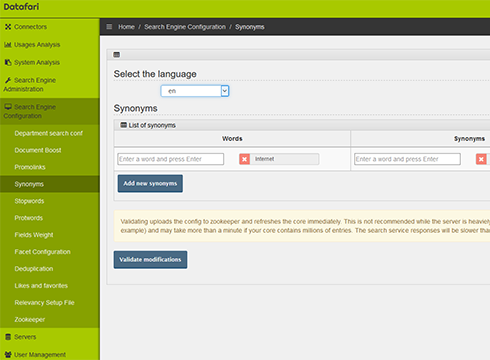
Algorithmique
Notre algorithme est configurable par l'importance relative qu'on peut associer aux différentes composantes des documents (contenu, métadonnées). En même temps, il permet de mettre en avant des documents spécifiques pour des requêtes identifiées.
Sémantique
La Reconnaissance et l'Extraction d'Entités (dates, auteurs, numéros d'équipements ...) permet une meilleure compréhension des documents, entraînant un classement plus pertinence des résultats.
Contextuelle
Nous stockons les informations contextuelles (historique utilisateur, clics, département...) and nous utilisons ces données pour faire du classement orienté utilisateur. Notre R&D autour du Machine Learning nous permettra à termes d'optimiser les résultats de recherche par l'utilisation d'un réseau neuronal.
Ils nous font confiance
